
ついに発売された次世代GPU、RTX 5070(Blackwell)。
「これで画像生成が爆速になる!」と胸を躍らせてPCを新調したのも束の間、いざStable Diffusion WebUIを起動しようとすると……。
- 見たこともないエラーログの山
- なぜか立ち上がらないコンソール画面
- ネットで調べても「RTX 50シリーズ」の情報が少なすぎる…
私もRTX 3070 Tiから乗り換えた直後、この「最新世代特有の壁」にぶち当たりました。
メモリを64GB積んだ最強環境のはずが、ただの置物になりかけたのです。
そこで私が頼ったのが、GoogleのAI「Gemini」でした。
エラーログを読み込ませ、対話を繰り返すことで、環境を汚さず一括管理できる「Stability Matrix」を使った「Blackwell世代専用」の最適な構築手順に辿り着くことができたのです。
この記事を読めば、以下の悩みがすべて解決します。
- RTX 5070環境でStable Diffusionを「最短」で導入する方法
- Stability Matrixを使った「失敗しない」インストール手順
- 50シリーズ特有の起動エラー(依存関係)を解消する設定ポイント
- 【検証】3070 Tiと比較して実感した「異次元の生成スピード」
最新パーツで最高のAIライフをスタートさせるための「正解」を、実体験ベースで余すことなくお伝えします。
まずは、なぜStability Matrixが必要なのか? その理由から見ていきましょう。
RTX 5070(Blackwell)環境でStability Matrixが「一択」である3つの理由
これまでStable Diffusionを導入するには、Pythonをインストールし、Gitでソースコードをクローンし、複雑なコマンドを打つ……という「儀式」が必要でした。
しかし、最新のBlackwell世代でそんな「複雑で管理が難しい構築方法」を繰り返すのは、PC環境を常にクリーンに保ちたい視点で見てもリスクが大きすぎます。
私がStability Matrix「一択」だと断言する理由は、主にこの3点です。
💡Stability Matrix「一択」である3つの理由
- 環境を汚さない「ポータブル設計」
PC全体にPythonを入れず、専用の仮想環境を自動作成。他のアプリとの干渉を防ぎます。
- 複数のツールを1箇所で一括管理
WebUIやComfyUIを1クリックで切り替え。モデル共有機能でSSDの容量も節約できます。
- 最新ハードウェアへの自動最適化
RTX 5070に必要な依存関係(Torch/CUDA)をツールが自動判別して導入してくれます。
メリットがわかったところで、さっそくStability Matrixを導入していきましょう。
Blackwellのパワーを無駄にしないための、ちょっとしたコツもあわせて紹介します。
RTX 5070のポテンシャルを100%引き出す、ストレージの「推奨スペック」と空き容量
【重要】SATA接続のSSDや外付けドライブでは、データ転送がボトルネックとなりRTX 5070の性能を活かしきれないため、インストール先は「内蔵の高速なNVMe SSD(M.2 SSD)」を強く推奨します。
Stable Diffusionでは数GBのモデルデータを頻繁にロードするため、ストレージの速度が「作業のリズム」を決定づけます。
10秒の「待ち」をゼロに | NVMe SSDがもたらす圧倒的なスピード感
モデルを切り替えるたびに発生する待ち時間は、ドライブの転送速度でこれほど変わります。
| ドライブ種類 | 転送速度(目安) | ロード時間(実測) | 体感のイメージ |
|---|---|---|---|
| SATA SSD | 約500MB/s | 約10〜20秒 | 読み込みのたびに一呼吸待つ |
| NVMe SSD | 約5,000MB/s〜 | 約1〜3秒 | クリックした瞬間に終わる |
RTX 5070という強力なエンジンを積んでいても、データの供給(ストレージ)が遅ければその真価は発揮できません。
「ゼロ秒体験」ができるNVMe SSD(M.2 SSD)」こそ、最新環境には必須の選択です。
100GBでは足りない?創作に没頭するための「現実的な容量」
初期設定直後は数十GBで収まりますが、実際に使い始めると以下のデータが猛烈な勢いで増大します。
- モデル・LoRAの「沼」
1つ5GB前後のモデルを10個入れるだけで50GB。気に入った画風(LoRA)を数点追加するだけで、すぐに100GB単位を消費します。
- 高画質画像の蓄積
RTX 5070は生成速度が速いため、数千枚の画像を書き出すのもあっという間です。高画質な画像ほど1枚あたりのサイズが大きく、無視できない容量になります。
「とりあえず動かす」なら200GBでも足りますが、削除を繰り返す手間に時間を奪われないためには、500GB以上の空きを確保しておくのが現実的なラインです。
私は現在、Stable Diffusion専用に1TBのNVMe SSD(M.2 SSD)を割り当てていますが、これにして本当に良かったと実感しています。
「これ面白そう」と思ったモデルを容量不足の警告に怯えることなく即座に試せる。
この「管理の手間からの解放」こそが、創作意欲を維持するための最高のアップグレードになります。
【完全図解】RTX 5070のパワーを解放!Stability Matrixの導入手順(最短ルート)
SSDの準備ができたら、いよいよRTX 5070の性能をフルに引き出す「Stability Matrix」の環境構築を進めます。
高速なSSD、そして最新のGPU。これらが噛み合ったときに発揮される圧倒的なパフォーマンスには、私も思わずニヤけてしまいました。あの「一瞬で画像が出る」感動を最短距離で味わってもらいたいので、サクッと導入を進めていきましょう。
STEP 1:Stability Matrix本体のダウンロード
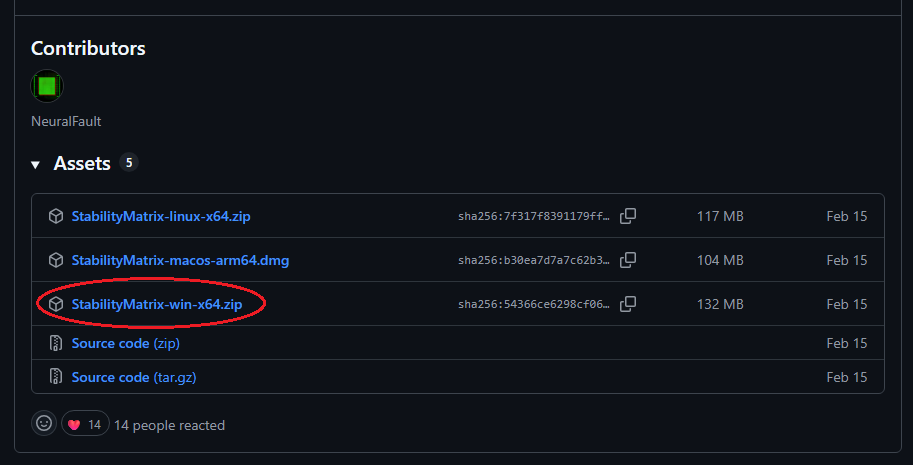
Stability Matrix公式配布ページ(GitHub)へアクセスします。
ページ下部の「Assets」から StabilityMatrix-win-x64.zip をクリックして保存します。
ダウンロードしたzipファイルを右クリックし、「すべて展開」を選択して解凍します。
※解凍して出てきたフォルダの中に StabilityMatrix.exe があることを確認してください。
STEP 2:専用フォルダの作成とexeファイルの配置
まずは、高速なNVMe SSD(Dドライブなど)に、Stability Matrixの保存フォルダを作成します。
ここを起点にすることで、将来のバックアップや移行が劇的に楽になります。
NVMe SSDのドライブ直下に、StabilityMatrix という名前で新しいフォルダを作成します。
※フォルダ名は自由ですが、エラー防止のため必ず「半角英数字」で作成してください(日本語などの全角文字は厳禁です)。
STEP 1で解凍した StabilityMatrix.exe を、作成した StabilityMatrx フォルダの直下へ移動させます。
STEP 3:Stability MatrixのセットアップとStable Diffusion WebUIの導入
配置したexeを起動して、同じフォルダ内へStability Matrixの環境を構築していきます。
exeと同じ場所にデータを集約させておくことで、将来のバックアップやPCの買い替え時も、このフォルダを移すだけで済む「身軽な構成」になります。
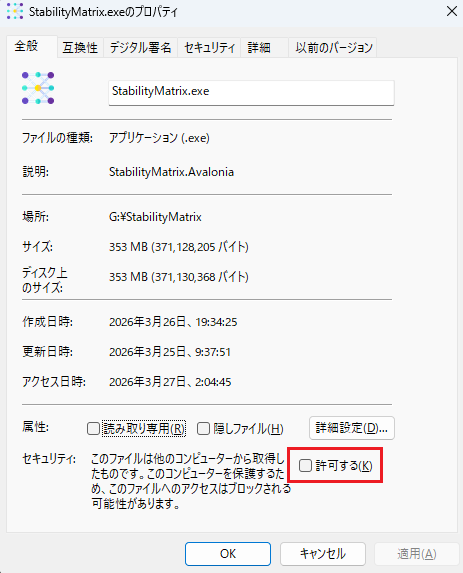
StabilityMatrix.exe を右クリックして「プロパティ」を開きます。「全般」タブの一番下にあるセキュリティの項目で「許可する」にチェックを入れて「適用」を押下し、ダブルクリックで起動します。
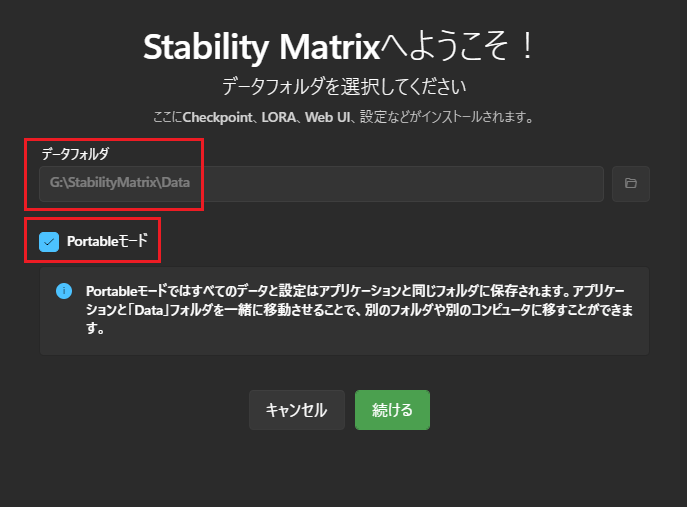
「Portableモード」にチェックを入れて「続ける」を押下します。
Portableモードにチェックを付けると、自動でデータフォルダの箇所にパスが入ります。
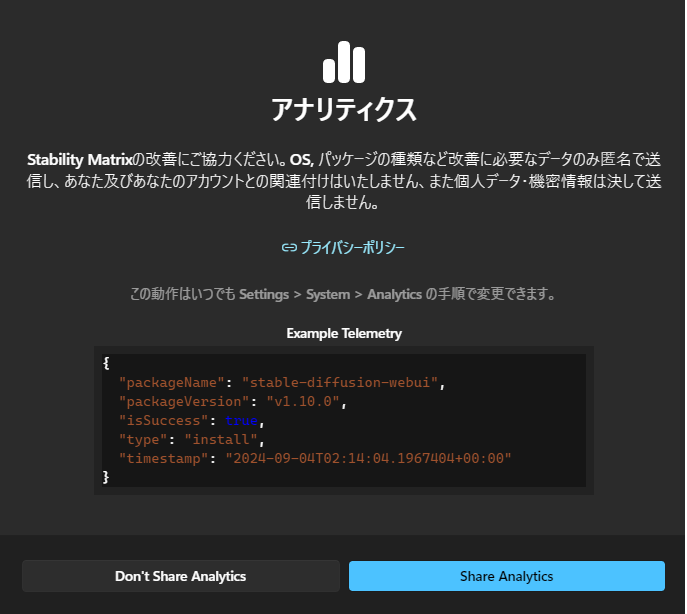
改善データを送信する場合は「Share Analytics」を、送信しない場合は「Don’t Share Analytics」を選択します。
パッケージ一覧から [Stable Diffusion WebUI Forge – Neo] をクリックします。
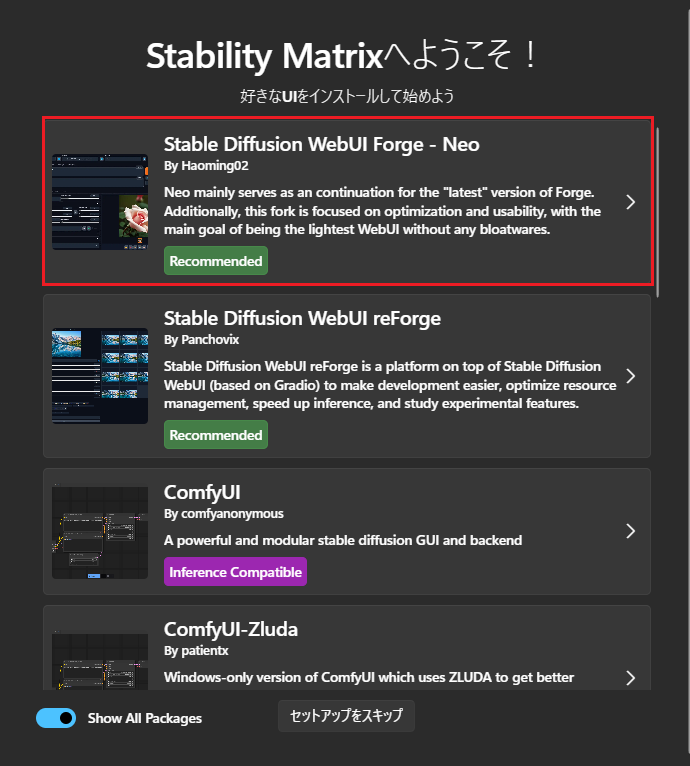
実は私、最初は「標準のWebUI (A1111)」をインストールしていました。
ですが、いざControlNet(ポーズ指定などの拡張機能)を入れようとした途端、原因不明のエラーが続発。 解決に何時間も費やし、正直「絶望」しました。
その後、藁にもすがる思いでForgeを試したところ、「最初からControlNetが組み込まれている」「設定不要で爆速」という別世界が待っていました。
RTX 5070という最新GPUの性能を余すことなく、かつ「エラーに悩まされず」に使いたいなら、私と同じ遠回りをせず、迷わずForgeを選んでください。
最後にModelの選択画面が出ますが、ここでは一部の代表的なモデルしか表示されません。
モデルは後からいくらでも追加できます。もしダウンロードに時間がかかりそうだったり、上手くいかない場合は、何も選択せずに閉じて先に進んでも全く問題ありません。
「閉じる」を選択した場合、その後1分程度で[Stable Diffusion WebUI Forge – Neo]のインストールが完了します。
STEP 4:Stable Diffusion WebUI Forge – Neoの環境最適化
以前のA1111や旧Forgeでは、手動でPyTorchを入れ替える必要がありました。
しかし、Stable Diffusion WebUI Forge – Neo なら最初から最新の「PyTorch 2.10 / CUDA 13.0」が組み込まれています! 手動インストールはスキップして、以下の「魔法の呪文」だけ設定しましょう。
Stability Matrixの「Packages」タブから、インストールしたStable Diffusion WebUI Forge – Neoの中央にある「歯車」マークのアイコンを開きます。
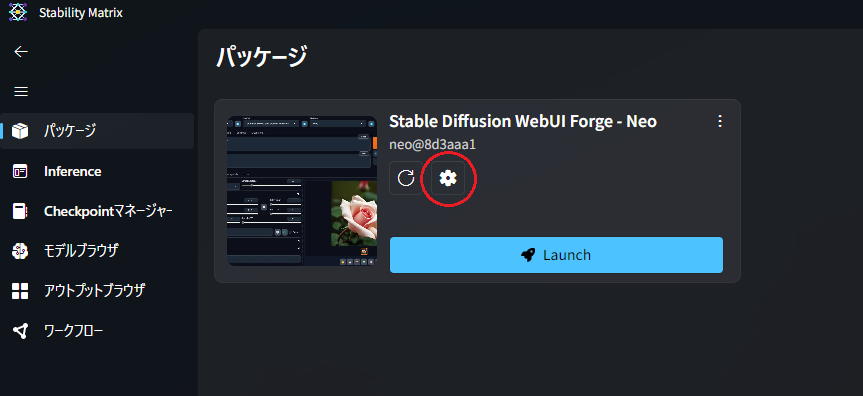
RTX 5070のような最新アーキテクチャでは、従来のVRAM管理よりも効率的な設定ができます。
以下の3つのチェックボックスを選択し「保存」します。
- –cuda-malloc
Blackwell世代で特に効果を発揮するメモリ管理最適化の設定です。
- –cuda-stream
処理を並列化し、最新コアの待ち時間を減らす設定です。
- –pin-shared-memory
大容量メモリとの転送効率を最大化する設定です。
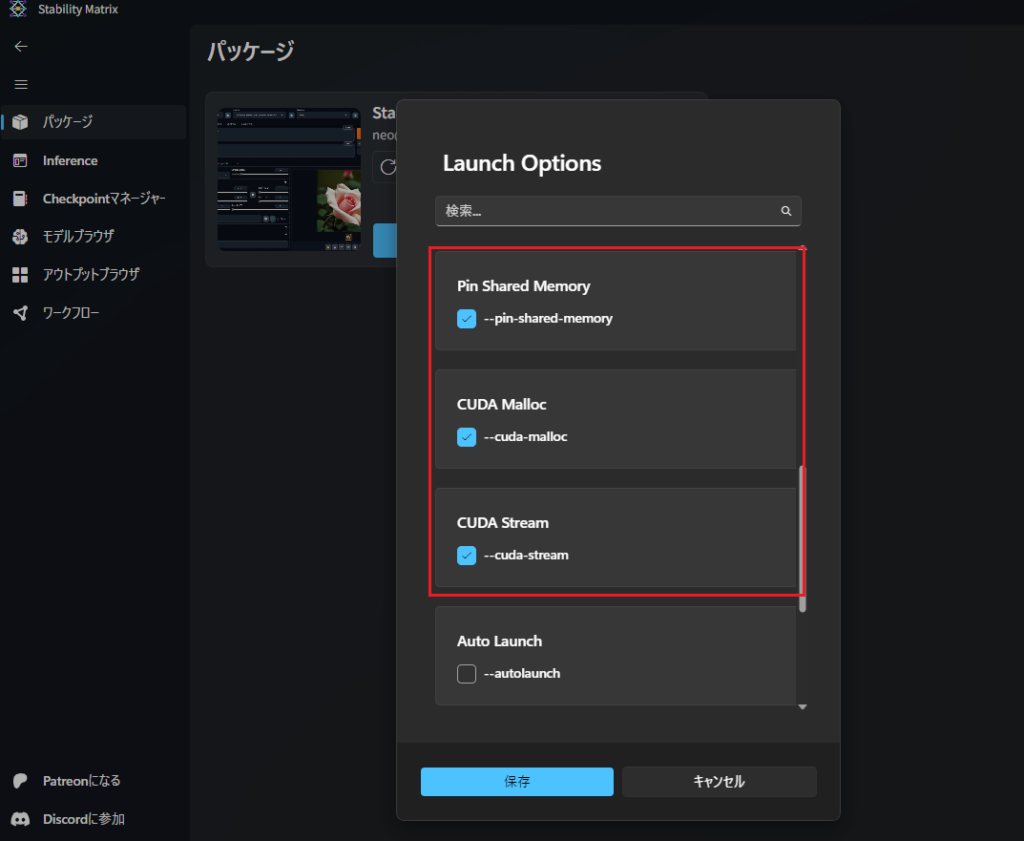
--xformers のチェックは入れないのが正解です。
RTX50シリーズのような最新世代では、Forge標準の「Flash Attention」の方が高速に動作します。
古い最適化を混ぜないのが、2026年現在のベストプラクティスです。
STEP 5:最初の1枚へ!「画像モデル」の探し方と導入手順
環境が整ったら、次は「絵の素」となるモデル(Checkpoint)を導入しましょう。
Stability Matrixならツール内の操作だけで完結します 。
もちろん「CIVITAI」などのサイトからダウンロードしても構いません。
左メニューの 「モデルブラウザ」 を開きます。
ここでは、世界中のクリエイターが公開したモデルを検索できます。
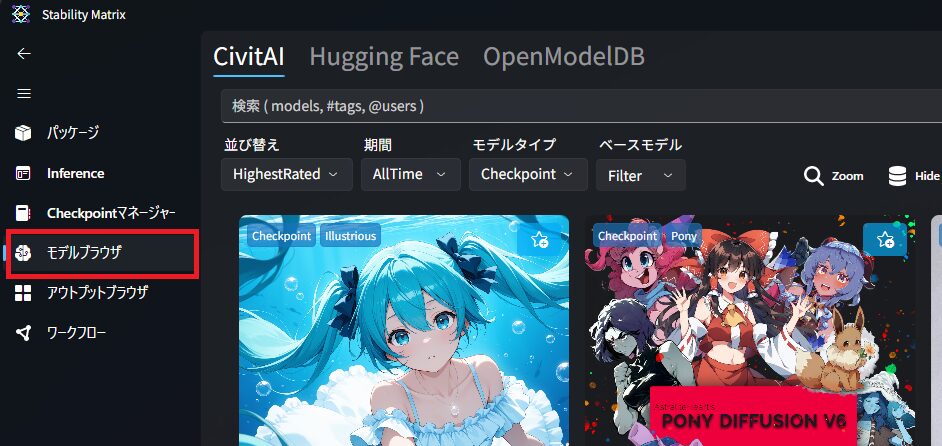
デモルタイプは「Checkpoint」を選択します。
アニメ系、実写系など、気に入ったモデルが見つかったらクリックしてください。
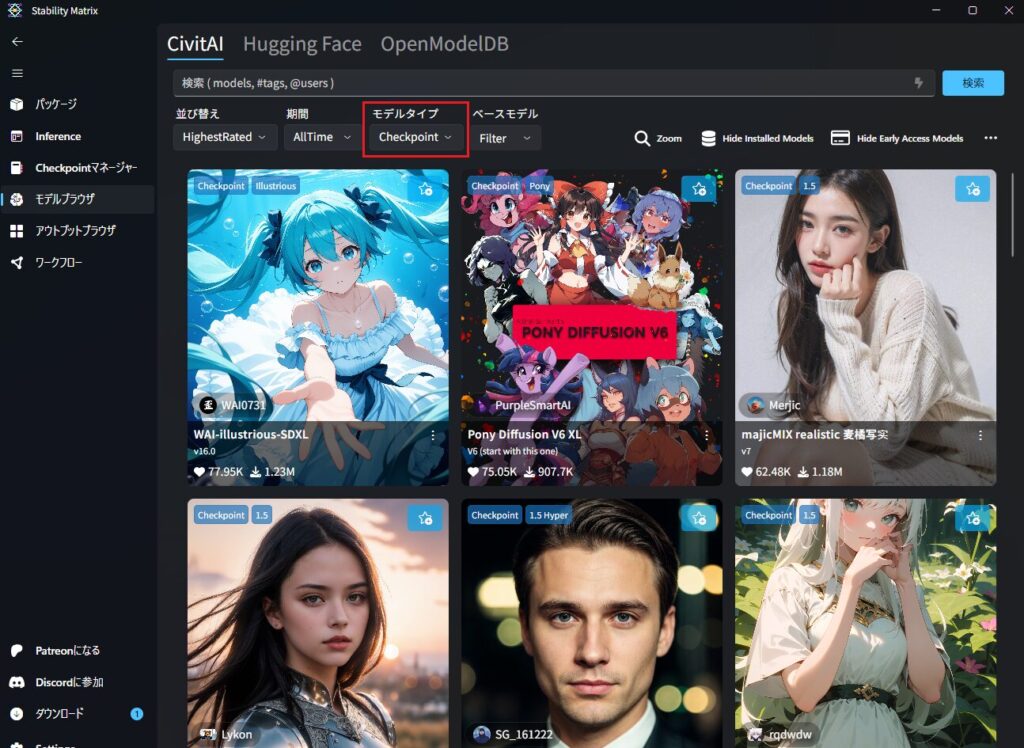
画面右下の「ダウンロード」をクリックします。
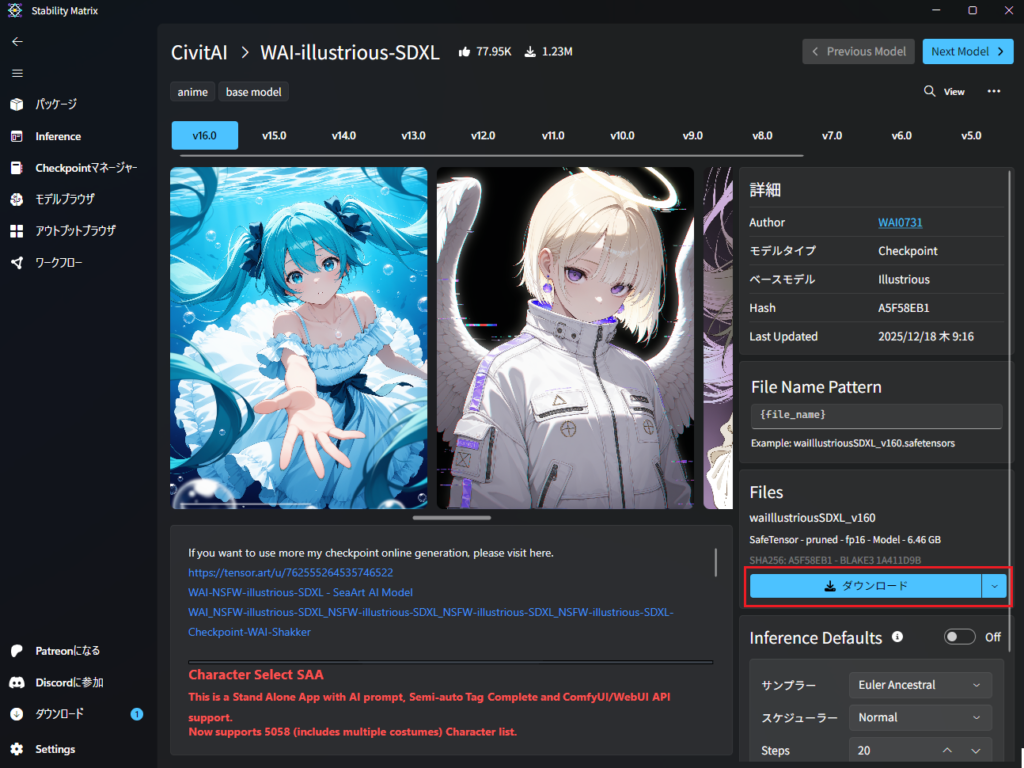
画面右下にモデルの保存場所が表示されます。
回線速度によりますが、ダウンロードが終わるまで少し時間がかかると思います。
ダウンロード後、手動でファイルを移動させる必要はありません。
【実践編】ついに初生成!RTX 5070で描く「最初の一枚」
ここからは、インストールした Stable Diffusion WebUI Forge – Neo を起動して、実際にAIに絵を描いてもらう手順を解説します 。
Stability Matrixの「パッケージ」画面から、[Stable Diffusion WebUI Forge – Neo] の 「Launch」 ボタンをクリックします 。
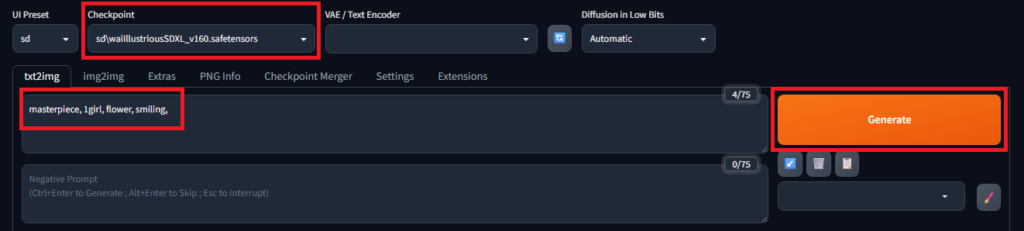
- モデルを選択する
- 画面左上の「Checkpoint」というプルダウンをクリックし、先ほどダウンロードしたモデルを選択します。
- リストに表示されない場合は右側の🔄ボタンを押してください。
- 「呪文(プロンプト)」を入力する
- 「Prompt」と書かれた上の大きな枠に、描きたい要素を英語で入力します。
- 例:masterpiece, 1girl, flower, smiling,
- 「Generate」をクリックする
- 画面右側にある「Generate」 ボタンをくクリックします。
- 画面右側にある「Generate」 ボタンをくクリックします。
- ここでは、上記以外はデフォルト設定のままとします。
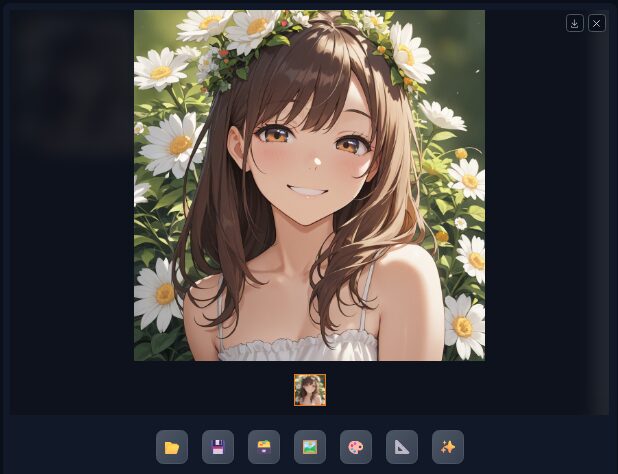
画面右下に生成された画像が表示されます。RTX 5070なら数秒で終わるはずです。
【検証】RTX 3070 Tiから乗り換えて実感した「異次元のスピード」
旧環境(3070 Ti)が手元にないため、厳密な横並び比較はできませんが、毎日生成ボタンを叩いていた「体感」と、今回の「実測」を照らし合わせれば、その差は歴然です。
生成時間の比較:10秒の壁が「一瞬」へ
以前の環境では時間がかかりすぎて敬遠しがちだった高解像度モデル(SDXL等)が、今回のRTX 5070環境では「常用できる速さ」に進化しました。
| 項目 | 旧環境(3070 Ti 記憶ベース) | 最新環境(RTX 5070 実測) |
|---|---|---|
| 標準生成 (512×512) | 約8〜10秒 | 約3~5秒 |
| 高解像度化 (SDXL等) | 約25秒〜40秒 | 約7〜10秒 |
以前は「よし、気合を入れて高画質化するぞ」と身構えていましたが、今ではその気負いすら不要です。
Blackwell世代のパワーとForge – Neoの組み合わせ、正直ここまで体感が変わるとは思っていませんでした
VRAM 12GBが生む「エラー知らず」の安心感
RTX 3070 Ti(VRAM 8GB)の最大の壁は、速度よりも「メモリ不足」でした。
- 旧環境の悩み
高解像度アップスケールやControlNetを併用するたびに、エラーが出て作業が中断されるストレス 。
- 新環境の解放感
VRAM12GBの余裕により、同じ呪文(プロンプト)でも解像度を上げて攻めることができます 。
一度もエラーで手が止まらないことが、これほど創作のモチベーションを維持してくれるとは思いませんでした。
まとめ:RTX 5070 × Forge – Neoでストレスのない画像生成ライフを
RTX 3070 Tiから5070への乗り換え。
最初は「最新世代ゆえの情報不足」に頭を抱えましたが、Geminiと対話を重ねることで、環境を汚さない「Stability Matrix」と最新の「Forge – Neo」を組み合わせた、納得のいく環境を構築できました。
改めて、今回構築した環境のポイントをまとめます。
- 環境をクリーンに保つ「Stability Matrix」
PythonやGitの複雑な設定に悩まされる「儀式」はもう卒業です。
- Blackwell世代の最適解「Forge – Neo」
最初から最新のPyTorchとCUDAが組み込まれているので、RTX50シリーズのパワーをフルに回せます。
- ポテンシャルを解放する「3つの最適化」
--cuda-mallocなどの設定を入れるだけで、メモリ管理が驚くほどスムーズになります。
検証の結果、SDXLでの高解像度生成が10秒を切るという、3070 Tiの頃には考えられなかったスピードを手に入れました。
以前は「よし、やるぞ」と気合を入れていた高画質化が、今では「とりあえず試してみよう」という軽い感覚でこなせます。この「作業のリズムが崩れない速さ」こそが、最新グラボに投資した一番の価値だと実感しています。
この記事が、私と同じように「最新世代の壁」にぶつかっている方のヒントになれば嬉しいです。
